^2 = \sum _^ \frac<(O_i - E_i)^2>. \end$$
Association Rule Learning
Association rule learning is a rule-based machine learning approach to discover interesting relationships, “IF-THEN” statements, in large datasets between variables [7]. One example is that “if a customer buys a computer or laptop (an item), s/he is likely to also buy anti-virus software (another item) at the same time”. Association rules are employed today in many application areas, including IoT services, medical diagnosis, usage behavior analytics, web usage mining, smartphone applications, cybersecurity applications, and bioinformatics. In comparison to sequence mining, association rule learning does not usually take into account the order of things within or across transactions. A common way of measuring the usefulness of association rules is to use its parameter, the ‘support’ and ‘confidence’, which is introduced in [7].
In the data mining literature, many association rule learning methods have been proposed, such as logic dependent [34], frequent pattern based [8, 49, 68], and tree-based [42]. The most popular association rule learning algorithms are summarized below.
- AIS and SETM: AIS is the first algorithm proposed by Agrawal et al. [7] for association rule mining. The AIS algorithm’s main downside is that too many candidate itemsets are generated, requiring more space and wasting a lot of effort. This algorithm calls for too many passes over the entire dataset to produce the rules. Another approach SETM [49] exhibits good performance and stable behavior with execution time; however, it suffers from the same flaw as the AIS algorithm.
- Apriori: For generating association rules for a given dataset, Agrawal et al. [8] proposed the Apriori, Apriori-TID, and Apriori-Hybrid algorithms. These later algorithms outperform the AIS and SETM mentioned above due to the Apriori property of frequent itemset [8]. The term ‘Apriori’ usually refers to having prior knowledge of frequent itemset properties. Apriori uses a “bottom-up” approach, where it generates the candidate itemsets. To reduce the search space, Apriori uses the property “all subsets of a frequent itemset must be frequent; and if an itemset is infrequent, then all its supersets must also be infrequent”. Another approach predictive Apriori [108] can also generate rules; however, it receives unexpected results as it combines both the support and confidence. The Apriori [8] is the widely applicable techniques in mining association rules.
- ECLAT: This technique was proposed by Zaki et al. [131] and stands for Equivalence Class Clustering and bottom-up Lattice Traversal. ECLAT uses a depth-first search to find frequent itemsets. In contrast to the Apriori [8] algorithm, which represents data in a horizontal pattern, it represents data vertically. Hence, the ECLAT algorithm is more efficient and scalable in the area of association rule learning. This algorithm is better suited for small and medium datasets whereas the Apriori algorithm is used for large datasets.
- FP-Growth: Another common association rule learning technique based on the frequent-pattern tree (FP-tree) proposed by Han et al. [42] is Frequent Pattern Growth, known as FP-Growth. The key difference with Apriori is that while generating rules, the Apriori algorithm [8] generates frequent candidate itemsets; on the other hand, the FP-growth algorithm [42] prevents candidate generation and thus produces a tree by the successful strategy of ‘divide and conquer’ approach. Due to its sophistication, however, FP-Tree is challenging to use in an interactive mining environment [133]. Thus, the FP-Tree would not fit into memory for massive data sets, making it challenging to process big data as well. Another solution is RARM (Rapid Association Rule Mining) proposed by Das et al. [26] but faces a related FP-tree issue [133].
- ABC-RuleMiner: A rule-based machine learning method, recently proposed in our earlier paper, by Sarker et al. [104], to discover the interesting non-redundant rules to provide real-world intelligent services. This algorithm effectively identifies the redundancy in associations by taking into account the impact or precedence of the related contextual features and discovers a set of non-redundant association rules. This algorithm first constructs an association generation tree (AGT), a top-down approach, and then extracts the association rules through traversing the tree. Thus, ABC-RuleMiner is more potent than traditional rule-based methods in terms of both non-redundant rule generation and intelligent decision-making, particularly in a context-aware smart computing environment, where human or user preferences are involved.
Among the association rule learning techniques discussed above, Apriori [8] is the most widely used algorithm for discovering association rules from a given dataset [133]. The main strength of the association learning technique is its comprehensiveness, as it generates all associations that satisfy the user-specified constraints, such as minimum support and confidence value. The ABC-RuleMiner approach [104] discussed earlier could give significant results in terms of non-redundant rule generation and intelligent decision-making for the relevant application areas in the real world.
Reinforcement Learning
Reinforcement learning (RL) is a machine learning technique that allows an agent to learn by trial and error in an interactive environment using input from its actions and experiences. Unlike supervised learning, which is based on given sample data or examples, the RL method is based on interacting with the environment. The problem to be solved in reinforcement learning (RL) is defined as a Markov Decision Process (MDP) [86], i.e., all about sequentially making decisions. An RL problem typically includes four elements such as Agent, Environment, Rewards, and Policy.
RL can be split roughly into Model-based and Model-free techniques. Model-based RL is the process of inferring optimal behavior from a model of the environment by performing actions and observing the results, which include the next state and the immediate reward [85]. AlphaZero, AlphaGo [113] are examples of the model-based approaches. On the other hand, a model-free approach does not use the distribution of the transition probability and the reward function associated with MDP. Q-learning, Deep Q Network, Monte Carlo Control, SARSA (State–Action–Reward–State–Action), etc. are some examples of model-free algorithms [52]. The policy network, which is required for model-based RL but not for model-free, is the key difference between model-free and model-based learning. In the following, we discuss the popular RL algorithms.
- Monte Carlo methods: Monte Carlo techniques, or Monte Carlo experiments, are a wide category of computational algorithms that rely on repeated random sampling to obtain numerical results [52]. The underlying concept is to use randomness to solve problems that are deterministic in principle. Optimization, numerical integration, and making drawings from the probability distribution are the three problem classes where Monte Carlo techniques are most commonly used.
- Q-learning: Q-learning is a model-free reinforcement learning algorithm for learning the quality of behaviors that tell an agent what action to take under what conditions [52]. It does not need a model of the environment (hence the term “model-free”), and it can deal with stochastic transitions and rewards without the need for adaptations. The ‘Q’ in Q-learning usually stands for quality, as the algorithm calculates the maximum expected rewards for a given behavior in a given state.
- Deep Q-learning: The basic working step in Deep Q-Learning [52] is that the initial state is fed into the neural network, which returns the Q-value of all possible actions as an output. Still, when we have a reasonably simple setting to overcome, Q-learning works well. However, when the number of states and actions becomes more complicated, deep learning can be used as a function approximator.
Reinforcement learning, along with supervised and unsupervised learning, is one of the basic machine learning paradigms. RL can be used to solve numerous real-world problems in various fields, such as game theory, control theory, operations analysis, information theory, simulation-based optimization, manufacturing, supply chain logistics, multi-agent systems, swarm intelligence, aircraft control, robot motion control, and many more.
Artificial Neural Network and Deep Learning
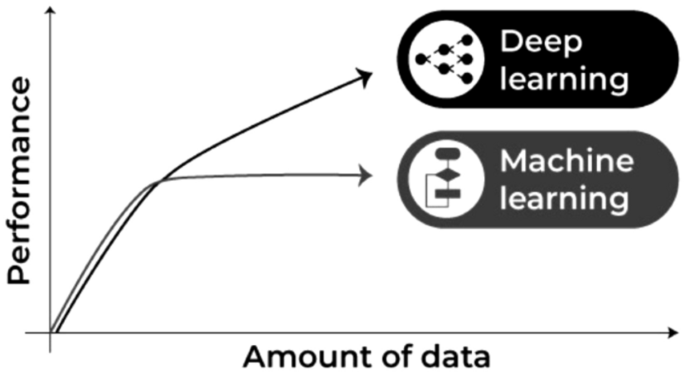
Deep learning is part of a wider family of artificial neural networks (ANN)-based machine learning approaches with representation learning. Deep learning provides a computational architecture by combining several processing layers, such as input, hidden, and output layers, to learn from data [41]. The main advantage of deep learning over traditional machine learning methods is its better performance in several cases, particularly learning from large datasets [105, 129]. Figure 9 shows a general performance of deep learning over machine learning considering the increasing amount of data. However, it may vary depending on the data characteristics and experimental set up.
The most common deep learning algorithms are: Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN, or ConvNet), Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) [96]. In the following, we discuss various types of deep learning methods that can be used to build effective data-driven models for various purposes.
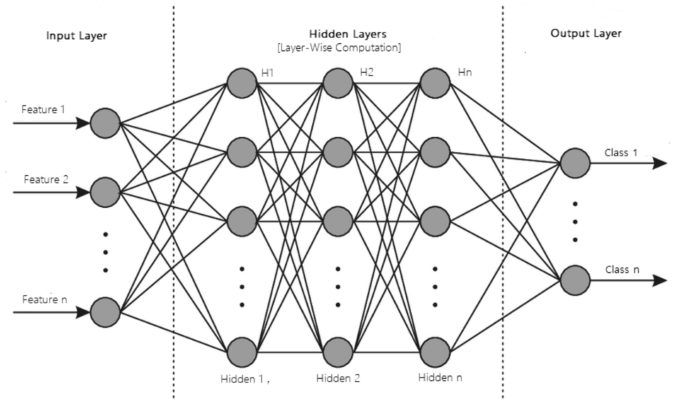
- MLP: The base architecture of deep learning, which is also known as the feed-forward artificial neural network, is called a multilayer perceptron (MLP) [82]. A typical MLP is a fully connected network consisting of an input layer, one or more hidden layers, and an output layer, as shown in Fig. 10. Each node in one layer connects to each node in the following layer at a certain weight. MLP utilizes the “Backpropagation” technique [41], the most “fundamental building block” in a neural network, to adjust the weight values internally while building the model. MLP is sensitive to scaling features and allows a variety of hyperparameters to be tuned, such as the number of hidden layers, neurons, and iterations, which can result in a computationally costly model.
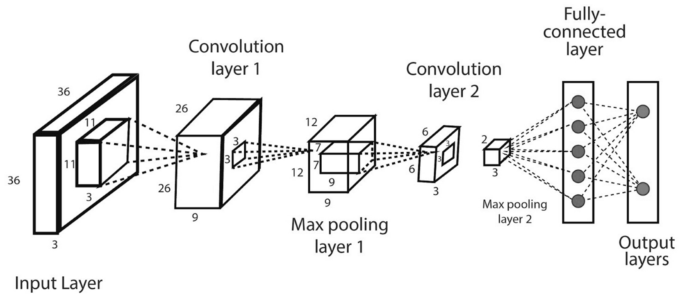
- CNN or ConvNet: The convolution neural network (CNN) [65] enhances the design of the standard ANN, consisting of convolutional layers, pooling layers, as well as fully connected layers, as shown in Fig. 11. As it takes the advantage of the two-dimensional (2D) structure of the input data, it is typically broadly used in several areas such as image and video recognition, image processing and classification, medical image analysis, natural language processing, etc. While CNN has a greater computational burden, without any manual intervention, it has the advantage of automatically detecting the important features, and hence CNN is considered to be more powerful than conventional ANN. A number of advanced deep learning models based on CNN can be used in the field, such as AlexNet [60], Xception [24], Inception [118], Visual Geometry Group (VGG) [44], ResNet [45], etc.
- LSTM-RNN: Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the area of deep learning [38]. LSTM has feedback links, unlike normal feed-forward neural networks. LSTM networks are well-suited for analyzing and learning sequential data, such as classifying, processing, and predicting data based on time series data, which differentiates it from other conventional networks. Thus, LSTM can be used when the data are in a sequential format, such as time, sentence, etc., and commonly applied in the area of time-series analysis, natural language processing, speech recognition, etc.
In addition to these most common deep learning methods discussed above, several other deep learning approaches [96] exist in the area for various purposes. For instance, the self-organizing map (SOM) [58] uses unsupervised learning to represent the high-dimensional data by a 2D grid map, thus achieving dimensionality reduction. The autoencoder (AE) [15] is another learning technique that is widely used for dimensionality reduction as well and feature extraction in unsupervised learning tasks. Restricted Boltzmann machines (RBM) [46] can be used for dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modeling. A deep belief network (DBN) is typically composed of simple, unsupervised networks such as restricted Boltzmann machines (RBMs) or autoencoders, and a backpropagation neural network (BPNN) [123]. A generative adversarial network (GAN) [39] is a form of the network for deep learning that can generate data with characteristics close to the actual data input. Transfer learning is currently very common because it can train deep neural networks with comparatively low data, which is typically the re-use of a new problem with a pre-trained model [124]. A brief discussion of these artificial neural networks (ANN) and deep learning (DL) models are summarized in our earlier paper Sarker et al. [96].
Overall, based on the learning techniques discussed above, we can conclude that various types of machine learning techniques, such as classification analysis, regression, data clustering, feature selection and extraction, and dimensionality reduction, association rule learning, reinforcement learning, or deep learning techniques, can play a significant role for various purposes according to their capabilities. In the following section, we discuss several application areas based on machine learning algorithms.
Applications of Machine Learning
In the current age of the Fourth Industrial Revolution (4IR), machine learning becomes popular in various application areas, because of its learning capabilities from the past and making intelligent decisions. In the following, we summarize and discuss ten popular application areas of machine learning technology.
- Predictive analytics and intelligent decision-making: A major application field of machine learning is intelligent decision-making by data-driven predictive analytics [21, 70]. The basis of predictive analytics is capturing and exploiting relationships between explanatory variables and predicted variables from previous events to predict the unknown outcome [41]. For instance, identifying suspects or criminals after a crime has been committed, or detecting credit card fraud as it happens. Another application, where machine learning algorithms can assist retailers in better understanding consumer preferences and behavior, better manage inventory, avoiding out-of-stock situations, and optimizing logistics and warehousing in e-commerce. Various machine learning algorithms such as decision trees, support vector machines, artificial neural networks, etc. [106, 125] are commonly used in the area. Since accurate predictions provide insight into the unknown, they can improve the decisions of industries, businesses, and almost any organization, including government agencies, e-commerce, telecommunications, banking and financial services, healthcare, sales and marketing, transportation, social networking, and many others.
- Cybersecurity and threat intelligence: Cybersecurity is one of the most essential areas of Industry 4.0. [114], which is typically the practice of protecting networks, systems, hardware, and data from digital attacks [114]. Machine learning has become a crucial cybersecurity technology that constantly learns by analyzing data to identify patterns, better detect malware in encrypted traffic, find insider threats, predict where bad neighborhoods are online, keep people safe while browsing, or secure data in the cloud by uncovering suspicious activity. For instance, clustering techniques can be used to identify cyber-anomalies, policy violations, etc. To detect various types of cyber-attacks or intrusions machine learning classification models by taking into account the impact of security features are useful [97]. Various deep learning-based security models can also be used on the large scale of security datasets [96, 129]. Moreover, security policy rules generated by association rule learning techniques can play a significant role to build a rule-based security system [105]. Thus, we can say that various learning techniques discussed in Sect. Machine Learning Tasks and Algorithms, can enable cybersecurity professionals to be more proactive inefficiently preventing threats and cyber-attacks.
- Internet of things (IoT) and smart cities: Internet of Things (IoT) is another essential area of Industry 4.0. [114], which turns everyday objects into smart objects by allowing them to transmit data and automate tasks without the need for human interaction. IoT is, therefore, considered to be the big frontier that can enhance almost all activities in our lives, such as smart governance, smart home, education, communication, transportation, retail, agriculture, health care, business, and many more [70]. Smart city is one of IoT’s core fields of application, using technologies to enhance city services and residents’ living experiences [132, 135]. As machine learning utilizes experience to recognize trends and create models that help predict future behavior and events, it has become a crucial technology for IoT applications [103]. For example, to predict traffic in smart cities, parking availability prediction, estimate the total usage of energy of the citizens for a particular period, make context-aware and timely decisions for the people, etc. are some tasks that can be solved using machine learning techniques according to the current needs of the people.
- Traffic prediction and transportation: Transportation systems have become a crucial component of every country’s economic development. Nonetheless, several cities around the world are experiencing an excessive rise in traffic volume, resulting in serious issues such as delays, traffic congestion, higher fuel prices, increased CO \(_2\) pollution, accidents, emergencies, and a decline in modern society’s quality of life [40]. Thus, an intelligent transportation system through predicting future traffic is important, which is an indispensable part of a smart city. Accurate traffic prediction based on machine and deep learning modeling can help to minimize the issues [17, 30, 31]. For example, based on the travel history and trend of traveling through various routes, machine learning can assist transportation companies in predicting possible issues that may occur on specific routes and recommending their customers to take a different path. Ultimately, these learning-based data-driven models help improve traffic flow, increase the usage and efficiency of sustainable modes of transportation, and limit real-world disruption by modeling and visualizing future changes.
- Healthcare and COVID-19 pandemic: Machine learning can help to solve diagnostic and prognostic problems in a variety of medical domains, such as disease prediction, medical knowledge extraction, detecting regularities in data, patient management, etc. [33, 77, 112]. Coronavirus disease (COVID-19) is an infectious disease caused by a newly discovered coronavirus, according to the World Health Organization (WHO) [3]. Recently, the learning techniques have become popular in the battle against COVID-19 [61, 63]. For the COVID-19 pandemic, the learning techniques are used to classify patients at high risk, their mortality rate, and other anomalies [61]. It can also be used to better understand the virus’s origin, COVID-19 outbreak prediction, as well as for disease diagnosis and treatment [14, 50]. With the help of machine learning, researchers can forecast where and when, the COVID-19 is likely to spread, and notify those regions to match the required arrangements. Deep learning also provides exciting solutions to the problems of medical image processing and is seen as a crucial technique for potential applications, particularly for COVID-19 pandemic [10, 78, 111]. Overall, machine and deep learning techniques can help to fight the COVID-19 virus and the pandemic as well as intelligent clinical decisions making in the domain of healthcare.
- E-commerce and product recommendations: Product recommendation is one of the most well known and widely used applications of machine learning, and it is one of the most prominent features of almost any e-commerce website today. Machine learning technology can assist businesses in analyzing their consumers’ purchasing histories and making customized product suggestions for their next purchase based on their behavior and preferences. E-commerce companies, for example, can easily position product suggestions and offers by analyzing browsing trends and click-through rates of specific items. Using predictive modeling based on machine learning techniques, many online retailers, such as Amazon [71], can better manage inventory, prevent out-of-stock situations, and optimize logistics and warehousing. The future of sales and marketing is the ability to capture, evaluate, and use consumer data to provide a customized shopping experience. Furthermore, machine learning techniques enable companies to create packages and content that are tailored to the needs of their customers, allowing them to maintain existing customers while attracting new ones.
- NLP and sentiment analysis: Natural language processing (NLP) involves the reading and understanding of spoken or written language through the medium of a computer [79, 103]. Thus, NLP helps computers, for instance, to read a text, hear speech, interpret it, analyze sentiment, and decide which aspects are significant, where machine learning techniques can be used. Virtual personal assistant, chatbot, speech recognition, document description, language or machine translation, etc. are some examples of NLP-related tasks. Sentiment Analysis [90] (also referred to as opinion mining or emotion AI) is an NLP sub-field that seeks to identify and extract public mood and views within a given text through blogs, reviews, social media, forums, news, etc. For instance, businesses and brands use sentiment analysis to understand the social sentiment of their brand, product, or service through social media platforms or the web as a whole. Overall, sentiment analysis is considered as a machine learning task that analyzes texts for polarity, such as “positive”, “negative”, or “neutral” along with more intense emotions like very happy, happy, sad, very sad, angry, have interest, or not interested etc.
- Image, speech and pattern recognition: Image recognition [36] is a well-known and widespread example of machine learning in the real world, which can identify an object as a digital image. For instance, to label an x-ray as cancerous or not, character recognition, or face detection in an image, tagging suggestions on social media, e.g., Facebook, are common examples of image recognition. Speech recognition [23] is also very popular that typically uses sound and linguistic models, e.g., Google Assistant, Cortana, Siri, Alexa, etc. [67], where machine learning methods are used. Pattern recognition [13] is defined as the automated recognition of patterns and regularities in data, e.g., image analysis. Several machine learning techniques such as classification, feature selection, clustering, or sequence labeling methods are used in the area.
- Sustainable agriculture: Agriculture is essential to the survival of all human activities [109]. Sustainable agriculture practices help to improve agricultural productivity while also reducing negative impacts on the environment [5, 25, 109]. The sustainable agriculture supply chains are knowledge-intensive and based on information, skills, technologies, etc., where knowledge transfer encourages farmers to enhance their decisions to adopt sustainable agriculture practices utilizing the increasing amount of data captured by emerging technologies, e.g., the Internet of Things (IoT), mobile technologies and devices, etc. [5, 53, 54]. Machine learning can be applied in various phases of sustainable agriculture, such as in the pre-production phase - for the prediction of crop yield, soil properties, irrigation requirements, etc.; in the production phase—for weather prediction, disease detection, weed detection, soil nutrient management, livestock management, etc.; in processing phase—for demand estimation, production planning, etc. and in the distribution phase - the inventory management, consumer analysis, etc.
- User behavior analytics and context-aware smartphone applications: Context-awareness is a system’s ability to capture knowledge about its surroundings at any moment and modify behaviors accordingly [28, 93]. Context-aware computing uses software and hardware to automatically collect and interpret data for direct responses. The mobile app development environment has been changed greatly with the power of AI, particularly, machine learning techniques through their learning capabilities from contextual data [103, 136]. Thus, the developers of mobile apps can rely on machine learning to create smart apps that can understand human behavior, support, and entertain users [107, 137, 140]. To build various personalized data-driven context-aware systems, such as smart interruption management, smart mobile recommendation, context-aware smart searching, decision-making that intelligently assist end mobile phone users in a pervasive computing environment, machine learning techniques are applicable. For example, context-aware association rules can be used to build an intelligent phone call application [104]. Clustering approaches are useful in capturing users’ diverse behavioral activities by taking into account data in time series [102]. To predict the future events in various contexts, the classification methods can be used [106, 139]. Thus, various learning techniques discussed in Sect. “Machine Learning Tasks and Algorithms” can help to build context-aware adaptive and smart applications according to the preferences of the mobile phone users.
In addition to these application areas, machine learning-based models can also apply to several other domains such as bioinformatics, cheminformatics, computer networks, DNA sequence classification, economics and banking, robotics, advanced engineering, and many more.
Challenges and Research Directions
Our study on machine learning algorithms for intelligent data analysis and applications opens several research issues in the area. Thus, in this section, we summarize and discuss the challenges faced and the potential research opportunities and future directions.
In general, the effectiveness and the efficiency of a machine learning-based solution depend on the nature and characteristics of the data, and the performance of the learning algorithms. To collect the data in the relevant domain, such as cybersecurity, IoT, healthcare and agriculture discussed in Sect. “Applications of Machine Learning” is not straightforward, although the current cyberspace enables the production of a huge amount of data with very high frequency. Thus, collecting useful data for the target machine learning-based applications, e.g., smart city applications, and their management is important to further analysis. Therefore, a more in-depth investigation of data collection methods is needed while working on the real-world data. Moreover, the historical data may contain many ambiguous values, missing values, outliers, and meaningless data. The machine learning algorithms, discussed in Sect “Machine Learning Tasks and Algorithms” highly impact on data quality, and availability for training, and consequently on the resultant model. Thus, to accurately clean and pre-process the diverse data collected from diverse sources is a challenging task. Therefore, effectively modifying or enhance existing pre-processing methods, or proposing new data preparation techniques are required to effectively use the learning algorithms in the associated application domain.
To analyze the data and extract insights, there exist many machine learning algorithms, summarized in Sect. “Machine Learning Tasks and Algorithms”. Thus, selecting a proper learning algorithm that is suitable for the target application is challenging. The reason is that the outcome of different learning algorithms may vary depending on the data characteristics [106]. Selecting a wrong learning algorithm would result in producing unexpected outcomes that may lead to loss of effort, as well as the model’s effectiveness and accuracy. In terms of model building, the techniques discussed in Sect. “Machine Learning Tasks and Algorithms” can directly be used to solve many real-world issues in diverse domains, such as cybersecurity, smart cities and healthcare summarized in Sect. “Applications of Machine Learning”. However, the hybrid learning model, e.g., the ensemble of methods, modifying or enhancement of the existing learning techniques, or designing new learning methods, could be a potential future work in the area.
Thus, the ultimate success of a machine learning-based solution and corresponding applications mainly depends on both the data and the learning algorithms. If the data are bad to learn, such as non-representative, poor-quality, irrelevant features, or insufficient quantity for training, then the machine learning models may become useless or will produce lower accuracy. Therefore, effectively processing the data and handling the diverse learning algorithms are important, for a machine learning-based solution and eventually building intelligent applications.
Conclusion
In this paper, we have conducted a comprehensive overview of machine learning algorithms for intelligent data analysis and applications. According to our goal, we have briefly discussed how various types of machine learning methods can be used for making solutions to various real-world issues. A successful machine learning model depends on both the data and the performance of the learning algorithms. The sophisticated learning algorithms then need to be trained through the collected real-world data and knowledge related to the target application before the system can assist with intelligent decision-making. We also discussed several popular application areas based on machine learning techniques to highlight their applicability in various real-world issues. Finally, we have summarized and discussed the challenges faced and the potential research opportunities and future directions in the area. Therefore, the challenges that are identified create promising research opportunities in the field which must be addressed with effective solutions in various application areas. Overall, we believe that our study on machine learning-based solutions opens up a promising direction and can be used as a reference guide for potential research and applications for both academia and industry professionals as well as for decision-makers, from a technical point of view.
References
- Canadian institute of cybersecurity, university of new brunswick, iscx dataset, http://www.unb.ca/cic/datasets/index.html/ (Accessed on 20 October 2019).
- Cic-ddos2019 [online]. available: https://www.unb.ca/cic/datasets/ddos-2019.html/ (Accessed on 28 March 2020).
- World health organization: WHO. http://www.who.int/.
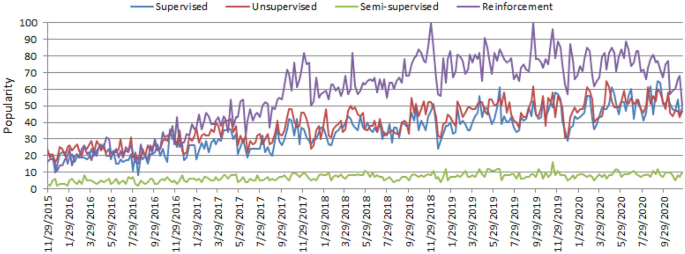
- Google trends. In https://trends.google.com/trends/, 2019.
- Adnan N, Nordin Shahrina Md, Rahman I, Noor A. The effects of knowledge transfer on farmers decision making toward sustainable agriculture practices. World J Sci Technol Sustain Dev. 2018.
- Agrawal R, Gehrke J, Gunopulos D, Raghavan P. Automatic subspace clustering of high dimensional data for data mining applications. In: Proceedings of the 1998 ACM SIGMOD international conference on Management of data. 1998; 94–105
- Agrawal R, Imieliński T, Swami A. Mining association rules between sets of items in large databases. In: ACM SIGMOD Record. ACM. 1993;22: 207–216
- Agrawal R, Gehrke J, Gunopulos D, Raghavan P. Fast algorithms for mining association rules. In: Proceedings of the International Joint Conference on Very Large Data Bases, Santiago Chile. 1994; 1215: 487–499.
- Aha DW, Kibler D, Albert M. Instance-based learning algorithms. Mach Learn. 1991;6(1):37–66. ArticleGoogle Scholar
- Alakus TB, Turkoglu I. Comparison of deep learning approaches to predict covid-19 infection. Chaos Solit Fract. 2020;140:
- Amit Y, Geman D. Shape quantization and recognition with randomized trees. Neural Comput. 1997;9(7):1545–88. ArticleGoogle Scholar
- Ankerst M, Breunig MM, Kriegel H-P, Sander J. Optics: ordering points to identify the clustering structure. ACM Sigmod Record. 1999;28(2):49–60. ArticleGoogle Scholar
- Anzai Y. Pattern recognition and machine learning. Elsevier; 2012. MATHGoogle Scholar
- Ardabili SF, Mosavi A, Ghamisi P, Ferdinand F, Varkonyi-Koczy AR, Reuter U, Rabczuk T, Atkinson PM. Covid-19 outbreak prediction with machine learning. Algorithms. 2020;13(10):249. ArticleMathSciNetGoogle Scholar
- Baldi P. Autoencoders, unsupervised learning, and deep architectures. In: Proceedings of ICML workshop on unsupervised and transfer learning, 2012; 37–49 .
- Balducci F, Impedovo D, Pirlo G. Machine learning applications on agricultural datasets for smart farm enhancement. Machines. 2018;6(3):38. ArticleGoogle Scholar
- Boukerche A, Wang J. Machine learning-based traffic prediction models for intelligent transportation systems. Comput Netw. 2020;181
- Breiman L. Bagging predictors. Mach Learn. 1996;24(2):123–40. ArticleMATHGoogle Scholar
- Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. ArticleMATHGoogle Scholar
- Breiman L, Friedman J, Stone CJ, Olshen RA. Classification and regression trees. CRC Press; 1984. MATHGoogle Scholar
- Cao L. Data science: a comprehensive overview. ACM Comput Surv (CSUR). 2017;50(3):43. Google Scholar
- Carpenter GA, Grossberg S. A massively parallel architecture for a self-organizing neural pattern recognition machine. Comput Vis Graph Image Process. 1987;37(1):54–115. ArticleMATHGoogle Scholar
- Chiu C-C, Sainath TN, Wu Y, Prabhavalkar R, Nguyen P, Chen Z, Kannan A, Weiss RJ, Rao K, Gonina E, et al. State-of-the-art speech recognition with sequence-to-sequence models. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018 pages 4774–4778. IEEE .
- Chollet F. Xception: deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017.
- Cobuloglu H, Büyüktahtakın IE. A stochastic multi-criteria decision analysis for sustainable biomass crop selection. Expert Syst Appl. 2015;42(15–16):6065–74. ArticleGoogle Scholar
- Das A, Ng W-K, Woon Y-K. Rapid association rule mining. In: Proceedings of the tenth international conference on Information and knowledge management, pages 474–481. ACM, 2001.
- de Amorim RC. Constrained clustering with minkowski weighted k-means. In: 2012 IEEE 13th International Symposium on Computational Intelligence and Informatics (CINTI), pages 13–17. IEEE, 2012.
- Dey AK. Understanding and using context. Person Ubiquit Comput. 2001;5(1):4–7. ArticleGoogle Scholar
- Eagle N, Pentland AS. Reality mining: sensing complex social systems. Person Ubiquit Comput. 2006;10(4):255–68. ArticleGoogle Scholar
- Essien A, Petrounias I, Sampaio P, Sampaio S. Improving urban traffic speed prediction using data source fusion and deep learning. In: 2019 IEEE International Conference on Big Data and Smart Computing (BigComp). IEEE. 2019: 1–8. .
- Essien A, Petrounias I, Sampaio P, Sampaio S. A deep-learning model for urban traffic flow prediction with traffic events mined from twitter. In: World Wide Web, 2020: 1–24 .
- Ester M, Kriegel H-P, Sander J, Xiaowei X, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd. 1996;96:226–31. Google Scholar
- Fatima M, Pasha M, et al. Survey of machine learning algorithms for disease diagnostic. J Intell Learn Syst Appl. 2017;9(01):1. Google Scholar
- Flach PA, Lachiche N. Confirmation-guided discovery of first-order rules with tertius. Mach Learn. 2001;42(1–2):61–95. ArticleMATHGoogle Scholar
- Freund Y, Schapire RE, et al. Experiments with a new boosting algorithm. In: Icml, Citeseer. 1996; 96: 148–156
- Fujiyoshi H, Hirakawa T, Yamashita T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019;43(4):244–52. ArticleGoogle Scholar
- Fukunaga K, Hostetler L. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans Inform Theory. 1975;21(1):32–40. ArticleMathSciNetMATHGoogle Scholar
- Goodfellow I, Bengio Y, Courville A, Bengio Y. Deep learning. Cambridge: MIT Press; 2016. MATHGoogle Scholar
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In: Advances in neural information processing systems. 2014: 2672–2680.
- Guerrero-Ibáñez J, Zeadally S, Contreras-Castillo J. Sensor technologies for intelligent transportation systems. Sensors. 2018;18(4):1212. ArticleGoogle Scholar
- Han J, Pei J, Kamber M. Data mining: concepts and techniques. Amsterdam: Elsevier; 2011. MATHGoogle Scholar
- Han J, Pei J, Yin Y. Mining frequent patterns without candidate generation. In: ACM Sigmod Record, ACM. 2000;29: 1–12.
- Harmon SA, Sanford TH, Sheng X, Turkbey EB, Roth H, Ziyue X, Yang D, Myronenko A, Anderson V, Amalou A, et al. Artificial intelligence for the detection of covid-19 pneumonia on chest ct using multinational datasets. Nat Commun. 2020;11(1):1–7. ArticleGoogle Scholar
- He K, Zhang X, Ren S, Sun J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell. 2015;37(9):1904–16. ArticleGoogle Scholar
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770–778.
- Hinton GE. A practical guide to training restricted boltzmann machines. In: Neural networks: Tricks of the trade. Springer. 2012; 599-619
- Holte RC. Very simple classification rules perform well on most commonly used datasets. Mach Learn. 1993;11(1):63–90. ArticleMATHGoogle Scholar
- Hotelling H. Analysis of a complex of statistical variables into principal components. J Edu Psychol. 1933;24(6):417. ArticleMATHGoogle Scholar
- Houtsma M, Swami A. Set-oriented mining for association rules in relational databases. In: Data Engineering, 1995. Proceedings of the Eleventh International Conference on, IEEE.1995:25–33.
- Jamshidi M, Lalbakhsh A, Talla J, Peroutka Z, Hadjilooei F, Lalbakhsh P, Jamshidi M, La Spada L, Mirmozafari M, Dehghani M, et al. Artificial intelligence and covid-19: deep learning approaches for diagnosis and treatment. IEEE Access. 2020;8:109581–95. ArticleGoogle Scholar
- John GH, Langley P. Estimating continuous distributions in bayesian classifiers. In: Proceedings of the Eleventh conference on Uncertainty in artificial intelligence, Morgan Kaufmann Publishers Inc. 1995; 338–345
- Kaelbling LP, Littman ML, Moore AW. Reinforcement learning: a survey. J Artif Intell Res. 1996;4:237–85. ArticleGoogle Scholar
- Kamble SS, Gunasekaran A, Gawankar SA. Sustainable industry 4.0 framework: a systematic literature review identifying the current trends and future perspectives. Process Saf Environ Protect. 2018;117:408–25.
- Kamble SS, Gunasekaran A, Gawankar SA. Achieving sustainable performance in a data-driven agriculture supply chain: a review for research and applications. Int J Prod Econ. 2020;219:179–94. ArticleGoogle Scholar
- Kaufman L, Rousseeuw PJ. Finding groups in data: an introduction to cluster analysis, vol. 344. John Wiley & Sons; 2009. MATHGoogle Scholar
- Keerthi SS, Shevade SK, Bhattacharyya C, Radha Krishna MK. Improvements to platt’s smo algorithm for svm classifier design. Neural Comput. 2001;13(3):637–49. ArticleMATHGoogle Scholar
- Khadse V, Mahalle PN, Biraris SV. An empirical comparison of supervised machine learning algorithms for internet of things data. In: 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), IEEE. 2018; 1–6
- Kohonen T. The self-organizing map. Proc IEEE. 1990;78(9):1464–80. ArticleGoogle Scholar
- Koroniotis N, Moustafa N, Sitnikova E, Turnbull B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: bot-iot dataset. Fut Gen Comput Syst. 2019;100:779–96. ArticleGoogle Scholar
- Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, 2012: 1097–1105
- Kushwaha S, Bahl S, Bagha AK, Parmar KS, Javaid M, Haleem A, Singh RP. Significant applications of machine learning for covid-19 pandemic. J Ind Integr Manag. 2020;5(4).
- Lade P, Ghosh R, Srinivasan S. Manufacturing analytics and industrial internet of things. IEEE Intell Syst. 2017;32(3):74–9. ArticleGoogle Scholar
- Lalmuanawma S, Hussain J, Chhakchhuak L. Applications of machine learning and artificial intelligence for covid-19 (sars-cov-2) pandemic: a review. Chaos Sol Fract. 2020:110059 .
- LeCessie S, Van Houwelingen JC. Ridge estimators in logistic regression. J R Stat Soc Ser C (Appl Stat). 1992;41(1):191–201. MATHGoogle Scholar
- LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–324. ArticleGoogle Scholar
- Liu H, Motoda H. Feature extraction, construction and selection: A data mining perspective, vol. 453. Springer Science & Business Media; 1998.
- López G, Quesada L, Guerrero LA. Alexa vs. siri vs. cortana vs. google assistant: a comparison of speech-based natural user interfaces. In: International Conference on Applied Human Factors and Ergonomics, Springer. 2017; 241–250.
- Liu B, HsuW, Ma Y. Integrating classification and association rule mining. In: Proceedings of the fourth international conference on knowledge discovery and data mining, 1998.
- MacQueen J, et al. Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, 1967;volume 1, pages 281–297. Oakland, CA, USA.
- Mahdavinejad MS, Rezvan M, Barekatain M, Adibi P, Barnaghi P, Sheth AP. Machine learning for internet of things data analysis: a survey. Digit Commun Netw. 2018;4(3):161–75. ArticleGoogle Scholar
- Marchand A, Marx P. Automated product recommendations with preference-based explanations. J Retail. 2020;96(3):328–43. ArticleGoogle Scholar
- McCallum A. Information extraction: distilling structured data from unstructured text. Queue. 2005;3(9):48–57. ArticleGoogle Scholar
- Mehrotra A, Hendley R, Musolesi M. Prefminer: mining user’s preferences for intelligent mobile notification management. In: Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September, 2016; pp. 1223–1234. ACM, New York, USA. .
- Mohamadou Y, Halidou A, Kapen PT. A review of mathematical modeling, artificial intelligence and datasets used in the study, prediction and management of covid-19. Appl Intell. 2020;50(11):3913–25. ArticleGoogle Scholar
- Mohammed M, Khan MB, Bashier Mohammed BE. Machine learning: algorithms and applications. CRC Press; 2016. BookGoogle Scholar
- Moustafa N, Slay J. Unsw-nb15: a comprehensive data set for network intrusion detection systems (unsw-nb15 network data set). In: 2015 military communications and information systems conference (MilCIS), 2015;pages 1–6. IEEE .
- Nilashi M, Ibrahim OB, Ahmadi H, Shahmoradi L. An analytical method for diseases prediction using machine learning techniques. Comput Chem Eng. 2017;106:212–23. ArticleGoogle Scholar
- Yujin O, Park S, Ye JC. Deep learning covid-19 features on cxr using limited training data sets. IEEE Trans Med Imaging. 2020;39(8):2688–700. ArticleGoogle Scholar
- Otter DW, Medina JR , Kalita JK. A survey of the usages of deep learning for natural language processing. IEEE Trans Neural Netw Learn Syst. 2020.
- Park H-S, Jun C-H. A simple and fast algorithm for k-medoids clustering. Expert Syst Appl. 2009;36(2):3336–41. ArticleGoogle Scholar
- Liii Pearson K. on lines and planes of closest fit to systems of points in space. Lond Edinb Dublin Philos Mag J Sci. 1901;2(11):559–72. ArticleGoogle Scholar
- Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, et al. Scikit-learn: machine learning in python. J Mach Learn Res. 2011;12:2825–30. MathSciNetMATHGoogle Scholar
- Perveen S, Shahbaz M, Keshavjee K, Guergachi A. Metabolic syndrome and development of diabetes mellitus: predictive modeling based on machine learning techniques. IEEE Access. 2018;7:1365–75. ArticleGoogle Scholar
- Santi P, Ram D, Rob C, Nathan E. Behavior-based adaptive call predictor. ACM Trans Auton Adapt Syst. 2011;6(3):21:1–21:28.
- Polydoros AS, Nalpantidis L. Survey of model-based reinforcement learning: applications on robotics. J Intell Robot Syst. 2017;86(2):153–73. ArticleGoogle Scholar
- Puterman ML. Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons; 2014. MATHGoogle Scholar
- Quinlan JR. Induction of decision trees. Mach Learn. 1986;1:81–106. ArticleGoogle Scholar
- Quinlan JR. C4.5: programs for machine learning. Mach Learn. 1993.
- Rasmussen C. The infinite gaussian mixture model. Adv Neural Inform Process Syst. 1999;12:554–60. Google Scholar
- Ravi K, Ravi V. A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowl Syst. 2015;89:14–46. ArticleGoogle Scholar
- Rokach L. A survey of clustering algorithms. In: Data mining and knowledge discovery handbook, pages 269–298. Springer, 2010.
- Safdar S, Zafar S, Zafar N, Khan NF. Machine learning based decision support systems (dss) for heart disease diagnosis: a review. Artif Intell Rev. 2018;50(4):597–623. ArticleGoogle Scholar
- Sarker IH. Context-aware rule learning from smartphone data: survey, challenges and future directions. J Big Data. 2019;6(1):1–25. ArticleMathSciNetGoogle Scholar
- Sarker IH. A machine learning based robust prediction model for real-life mobile phone data. Internet Things. 2019;5:180–93. ArticleGoogle Scholar
- Sarker IH. Ai-driven cybersecurity: an overview, security intelligence modeling and research directions. SN Comput Sci. 2021.
- Sarker IH. Deep cybersecurity: a comprehensive overview from neural network and deep learning perspective. SN Comput Sci. 2021.
- Sarker IH, Abushark YB, Alsolami F, Khan A. Intrudtree: a machine learning based cyber security intrusion detection model. Symmetry. 2020;12(5):754. ArticleGoogle Scholar
- Sarker IH, Abushark YB, Khan A. Contextpca: predicting context-aware smartphone apps usage based on machine learning techniques. Symmetry. 2020;12(4):499. ArticleGoogle Scholar
- Sarker IH, Alqahtani H, Alsolami F, Khan A, Abushark YB, Siddiqui MK. Context pre-modeling: an empirical analysis for classification based user-centric context-aware predictive modeling. J Big Data. 2020;7(1):1–23. ArticleGoogle Scholar
- Sarker IH, Alan C, Jun H, Khan AI, Abushark YB, Khaled S. Behavdt: a behavioral decision tree learning to build user-centric context-aware predictive model. Mob Netw Appl. 2019; 1–11.
- Sarker IH, Colman A, Kabir MA, Han J. Phone call log as a context source to modeling individual user behavior. In: Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing (Ubicomp): Adjunct, Germany, pages 630–634. ACM, 2016.
- Sarker IH, Colman A, Kabir MA, Han J. Individualized time-series segmentation for mining mobile phone user behavior. Comput J Oxf Univ UK. 2018;61(3):349–68. Google Scholar
- Sarker IH, Hoque MM, MdK Uddin, Tawfeeq A. Mobile data science and intelligent apps: concepts, ai-based modeling and research directions. Mob Netw Appl, pages 1–19, 2020.
- Sarker IH, Kayes ASM. Abc-ruleminer: user behavioral rule-based machine learning method for context-aware intelligent services. J Netw Comput Appl. 2020; page 102762
- Sarker IH, Kayes ASM, Badsha S, Alqahtani H, Watters P, Ng A. Cybersecurity data science: an overview from machine learning perspective. J Big Data. 2020;7(1):1–29. ArticleGoogle Scholar
- Sarker IH, Watters P, Kayes ASM. Effectiveness analysis of machine learning classification models for predicting personalized context-aware smartphone usage. J Big Data. 2019;6(1):1–28. ArticleGoogle Scholar
- Sarker IH, Salah K. Appspred: predicting context-aware smartphone apps using random forest learning. Internet Things. 2019;8:
- Scheffer T. Finding association rules that trade support optimally against confidence. Intell Data Anal. 2005;9(4):381–95. ArticleGoogle Scholar
- Sharma R, Kamble SS, Gunasekaran A, Kumar V, Kumar A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput Oper Res. 2020;119:
- Shengli S, Ling CX. Hybrid cost-sensitive decision tree, knowledge discovery in databases. In: PKDD 2005, Proceedings of 9th European Conference on Principles and Practice of Knowledge Discovery in Databases. Lecture Notes in Computer Science, volume 3721, 2005.
- Shorten C, Khoshgoftaar TM, Furht B. Deep learning applications for covid-19. J Big Data. 2021;8(1):1–54. ArticleGoogle Scholar
- Gökhan S, Nevin Y. Data analysis in health and big data: a machine learning medical diagnosis model based on patients’ complaints. Commun Stat Theory Methods. 2019;1–10
- Silver D, Huang A, Maddison CJ, Guez A, Sifre L, Van Den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, et al. Mastering the game of go with deep neural networks and tree search. nature. 2016;529(7587):484–9.
- Ślusarczyk B. Industry 4.0: Are we ready? Polish J Manag Stud. 17, 2018.
- Sneath Peter HA. The application of computers to taxonomy. J Gen Microbiol. 1957;17(1).
- Sorensen T. Method of establishing groups of equal amplitude in plant sociology based on similarity of species. Biol Skr. 1948; 5.
- Srinivasan V, Moghaddam S, Mukherji A. Mobileminer: mining your frequent patterns on your phone. In: Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13-17 September, pp. 389–400. ACM, New York, USA. 2014.
- Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015; pages 1–9.
- Tavallaee M, Bagheri E, Lu W, Ghorbani AA. A detailed analysis of the kdd cup 99 data set. In. IEEE symposium on computational intelligence for security and defense applications. IEEE. 2009;2009:1–6. Google Scholar
- Tsagkias M. Tracy HK, Surya K, Vanessa M, de Rijke M. Challenges and research opportunities in ecommerce search and recommendations. In: ACM SIGIR Forum. volume 54. NY, USA: ACM New York; 2021. p. 1–23.
- Wagstaff K, Cardie C, Rogers S, Schrödl S, et al. Constrained k-means clustering with background knowledge. Icml. 2001;1:577–84. Google Scholar
- Wang W, Yang J, Muntz R, et al. Sting: a statistical information grid approach to spatial data mining. VLDB. 1997;97:186–95. Google Scholar
- Wei P, Li Y, Zhang Z, Tao H, Li Z, Liu D. An optimization method for intrusion detection classification model based on deep belief network. IEEE Access. 2019;7:87593–605. ArticleGoogle Scholar
- Weiss K, Khoshgoftaar TM, Wang DD. A survey of transfer learning. J Big data. 2016;3(1):9. ArticleGoogle Scholar
- Witten IH, Frank E. Data Mining: Practical machine learning tools and techniques. Morgan Kaufmann; 2005.
- Witten IH, Frank E, Trigg LE, Hall MA, Holmes G, Cunningham SJ. Weka: practical machine learning tools and techniques with java implementations. 1999.
- Wu C-C, Yen-Liang C, Yi-Hung L, Xiang-Yu Y. Decision tree induction with a constrained number of leaf nodes. Appl Intell. 2016;45(3):673–85. ArticleGoogle Scholar
- Wu X, Kumar V, Quinlan JR, Ghosh J, Yang Q, Motoda H, McLachlan GJ, Ng A, Liu B, Philip SY, et al. Top 10 algorithms in data mining. Knowl Inform Syst. 2008;14(1):1–37. ArticleGoogle Scholar
- Xin Y, Kong L, Liu Z, Chen Y, Li Y, Zhu H, Gao M, Hou H, Wang C. Machine learning and deep learning methods for cybersecurity. IEEE Access. 2018;6:35365–81. ArticleGoogle Scholar
- Xu D, Yingjie T. A comprehensive survey of clustering algorithms. Ann Data Sci. 2015;2(2):165–93. ArticleGoogle Scholar
- Zaki MJ. Scalable algorithms for association mining. IEEE Trans Knowl Data Eng. 2000;12(3):372–90. ArticleGoogle Scholar
- Zanella A, Bui N, Castellani A, Vangelista L, Zorzi M. Internet of things for smart cities. IEEE Internet Things J. 2014;1(1):22–32. ArticleGoogle Scholar
- Zhao Q, Bhowmick SS. Association rule mining: a survey. Singapore: Nanyang Technological University; 2003. Google Scholar
- Zheng T, Xie W, Xu L, He X, Zhang Y, You M, Yang G, Chen Y. A machine learning-based framework to identify type 2 diabetes through electronic health records. Int J Med Inform. 2017;97:120–7. ArticleGoogle Scholar
- Zheng Y, Rajasegarar S, Leckie C. Parking availability prediction for sensor-enabled car parks in smart cities. In: Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), 2015 IEEE Tenth International Conference on. IEEE, 2015; pages 1–6.
- Zhu H, Cao H, Chen E, Xiong H, Tian J. Exploiting enriched contextual information for mobile app classification. In: Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, 2012; pages 1617–1621
- Zhu H, Chen E, Xiong H, Kuifei Y, Cao H, Tian J. Mining mobile user preferences for personalized context-aware recommendation. ACM Trans Intell Syst Technol (TIST). 2014;5(4):58. Google Scholar
- Zikang H, Yong Y, Guofeng Y, Xinyu Z. Sentiment analysis of agricultural product ecommerce review data based on deep learning. In: 2020 International Conference on Internet of Things and Intelligent Applications (ITIA), IEEE, 2020; pages 1–7
- Zulkernain S, Madiraju P, Ahamed SI. A context aware interruption management system for mobile devices. In: Mobile Wireless Middleware, Operating Systems, and Applications. Springer. 2010; pages 221–234
- Zulkernain S, Madiraju P, Ahamed S, Stamm K. A mobile intelligent interruption management system. J UCS. 2010;16(15):2060–80. Google Scholar
Author information
Authors and Affiliations
- Swinburne University of Technology, Melbourne, VIC, 3122, Australia Iqbal H. Sarker
- Department of Computer Science and Engineering, Chittagong University of Engineering & Technology, 4349, Chattogram, Bangladesh Iqbal H. Sarker
- Iqbal H. Sarker